6.5840:Lab1 - MapReduce
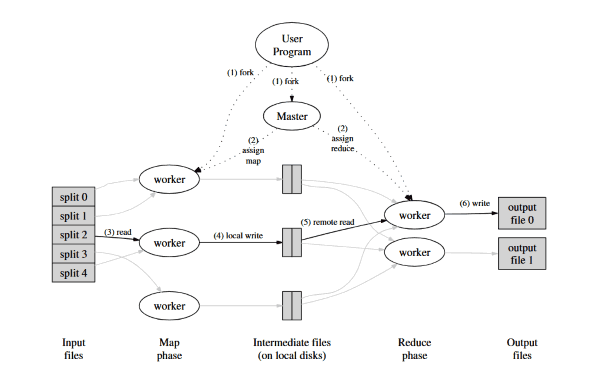
这里直接引用论文中的图片,本文会忽略一些东西,主要记录一下我自己的理解。
分布式系统的特性
可扩展性。通俗来讲就是如果我用一台计算机解决了一些问题,当我增加第二台计算机后,我只需要一半的时间就可以解决这些问题,或者说每分钟可以解决两倍数量的问题。这在MapReduce中体现为将一个大任务分解成很多的小任务,以便于多个worker同时处理任务。
可用性。经过精心的设计,在特定的错误类型下(如某台机器发生故障),系统仍然能够正常运行,仍然可以像没有出现错误一样,提供完整的服务。一般的方法如构建一个多副本系统,其中一个故障了,其他的还能运行,当然如果所有副本都故障了,系统就不再有可用性。这在MapReduce中体现为多个worker可以互为副本,其中一个worker发生故障,可以将其任务交给另一个worker来执行。
可恢复性。如果出现了问题,服务会停止工作,不再响应请求,之后有人来修复,并且在修复之后系统仍然可以正常运行,就像没有出现过问题一样,这是一个比可用性更弱的需求。实现可用性和可恢复性这两个特性,有很多方法,其中最重要的两个是非易失存储和副本。
一致性。包括多个副本之间要保持一致,不过强一致性的代价非常高,人们可能对弱一致性感兴趣。
MapReduce实验
与论文所描述的有些不同,实验推荐采用worker向Master请求任务,当然,这是一种简化的做法,实现起来相对比较容易。但有一点,这种情况下,Master处于一个较为被动的情景。其他方面与论文描述的差不多。
在我看来,实验的有一点设计的比较巧妙,那就是为了保证未完全完成的任务结果影响到其他正常任务,采用创建临时文件保存未完全完成的任务结果,待任务完全完成后进行文件改名的原子性操作。
很多细节我建议阅读论文以及具体实验任务和提示,这里呈上我自己的实现https://github.com/logicff/mit6.5840。
一点想法
关于如何按照论文所描述的那样让Master主动分配任务。我的想法是让能够处理任务的worker向Master暴露自己,然后Master将已暴露的worker相关信息保存起来,之后分配任务的时候就可以根据保存的信息进行调度,还有超时检测,相比实验中设置一个超时时间,我认为更加合理的是在已有worker信息的基础上采用心跳检测等机制。
关于如何在多台机器上运行实验。其实实验任务中已经给了提示,就是用TCP/IP代替Unix sockets。
关于进一步提升MapReduce的性能。其实之前的课堂视频上有人提到过采用流式(或者说流水线)的方法进一步提高效率,而不是让Reduce worker等待Map worker全部完成任务。